高性能推理框架对比:vLLM、LMDeploy与TensorRT-LLM
学习目标
- 理解高性能推理框架的核心技术原理
- 掌握主流推理框架的特点与优缺点
- 学会根据应用场景选择合适的推理框架
- 了解推理优化的关键技术和方法
高性能推理的核心挑战
大语言模型推理面临几个核心挑战,这些挑战驱动了专业推理框架的发展:
- 内存墙问题:模型参数和注意力计算需要大量显存
- 计算资源效率:如何最大化利用GPU/CPU计算能力
- 请求调度:如何高效处理多个并发请求
- 延迟与吞吐量平衡:如何在保持低延迟的同时提高系统吞吐量
- 灵活性与适配性:支持不同模型架构和硬件平台
vLLM框架
vLLM是Stanford大学开发的高性能LLM推理引擎,以其PagedAttention技术和高效的并发处理能力著称。
核心技术特点
PagedAttention
- 将KV缓存按页管理,类似操作系统的虚拟内存管理
- 显著减少内存碎片,提高显存利用率达30-40%
- 支持更长的上下文长度和更多并发请求
连续批处理(Continuous Batching)
- 动态添加新请求到正在处理的批次
- 避免传统批处理中因等待最长序列而造成的GPU资源浪费
- 显著提高并发处理能力
迭代式解码引擎
- 优化推理过程中的计算流程
- 减少GPU内核启动开销
- 提高生成阶段的吞吐量
主要优势
- 高显存效率:支持在有限显存下处理更多请求
- 优秀的并发性能:在多请求场景下表现突出
- 广泛的模型支持:兼容大多数主流LLM模型
- 易于集成:提供OpenAI兼容API接口
- 活跃的社区支持:更新迭代快,问题解决及时
局限性
- 较高的启动开销:首次加载模型时间较长
- 资源调度灵活性有限:自定义调度策略支持不足
- 分布式功能相对初级:跨节点扩展功能仍在发展中
LMDeploy框架
LMDeploy是由上海人工智能实验室(上海AI Lab)开发的端到端LLM部署工具,专注于亚洲市场的模型优化。
核心技术特点
量化技术
- AWQ(Activation-aware Weight Quantization)算法
- 支持W4A16(4位权重,16位激活)等多种精度
- 几乎无精度损失的模型量化
Blocked KV Cache
- 类似PagedAttention的内存管理机制
- 为中文等亚洲语言模型特别优化
- 减少内存碎片,提高内存利用率
高效计算核心
- 针对不同计算阶段的定制CUDA核心
- 优化前缀(Prefill)和解码(Decode)阶段计算
- 针对特定硬件平台的性能调优
主要优势
- 亚洲语言模型优化:对中文等亚洲语言模型有特殊优化
- 全流程部署工具:从模型转换、量化到部署的完整工具链
- 低精度推理:提供高质量量化实现
- 多平台支持:从服务器到移动端的部署方案
- Turbomind推理引擎:高性能C++/CUDA实现
局限性
- 支持模型相对较少:与vLLM相比支持的模型架构较少
- 文档与社区:英文文档和社区支持相对有限
- 工具集成度:与主流MLOps工具的集成度不如vLLM
TensorRT-LLM框架
TensorRT-LLM是NVIDIA推出的基于TensorRT的LLM推理优化框架,专为NVIDIA GPU平台设计。
核心技术特点
深度NVIDIA硬件优化
- 针对不同代NVIDIA GPU架构优化
- 利用Tensor Core等专用硬件单元
- 支持多种精度(FP16, INT8, INT4等)
高级图优化
- 计算图融合优化
- 内核自动调优(Kernel Auto-Tuning)
- 运算符合并与内存访问优化
分布式推理
- 张量并行(Tensor Parallelism)
- 流水线并行(Pipeline Parallelism)
- 多GPU/多节点协同推理
主要优势
- 极致性能:在NVIDIA硬件上提供最佳性能
- 企业级支持:NVIDIA官方支持和优化
- 完整工具生态:与NVIDIA AI生态系统无缝集成
- 高级分布式能力:成熟的多GPU/多节点并行推理
- 量化精度:高质量的量化实现与工具
局限性
- 硬件限制:仅适用于NVIDIA GPU
- 复杂度较高:配置和使用难度较大
- 灵活性:针对非标准模型架构的适配较复杂
- 学习曲线:相比其他框架学习成本较高
支持的硬件
vLLM
- GPU:
- NVIDIA CUDA(Volta、Turing、Ampere、Ada、Hopper 架构)
- AMD ROCm
- Intel XPU
- CPU:
- Intel/AMD x86
- ARM AArch64
- Apple Silicon
- IBM Z(S390X)
- 其他 AI 加速器:
- Google TPU
- Intel Gaudi
- AWS Neuron(包括 Trainium 和 Inferentia)
LMDeploy
LMDeploy 是由 InternLM 团队开发的用于大语言模型压缩、部署和服务的工具包,主要支持以下硬件平台:
GPU:
NVIDIA CUDA(20 系列及以上,推荐单卡 24GB 显存或多卡组合)
支持的 NVIDIA 显卡型号包括:
CUDA Compute Capability: sm75, sm80, sm86, sm89, sm90
- Volta(sm70): V100
- Turing(sm75): 20 系列,T4
- Ampere(sm80,sm86): 30 系列,A10, A16, A30, A100 等
- Ada Lovelace(sm89): 40 系列
- Hopper(sm90):H100(尚未深度优化)
NPU:
- 华为 Ascend(昇腾)平台,支持 BF16 推理,需使用 MindIE 框架进行适配
- Huawei 910b
| 架构/芯片名称 | 制造商 | 代表产品 | 主要用途 |
|---|---|---|---|
| Volta(SM70) | NVIDIA | Tesla V100 | AI 训练、HPC |
| Turing(SM75) | NVIDIA | RTX 20 系列、T4 | 图形渲染、AI 推理 |
| Ampere(SM80/SM86) | NVIDIA | RTX 30 系列、A100 等 | AI 训练与推理 |
| Ada Lovelace(SM89) | NVIDIA | RTX 40 系列 | 高端图形、AI 应用 |
| Hopper(SM90) | NVIDIA | H100、H200 | 大规模 AI 模型训练 |
| Ascend 910B | 华为 | Ascend 910B | AI 训练与推理 |
此外,vLLM 支持多种量化方法(如 GPTQ、AWQ、INT4、INT8、FP8 等),其在不同硬件平台上的兼容性详见官方文档。
支持的模型对比
| LLMs | VLMs |
|
|
三大框架的性能对比
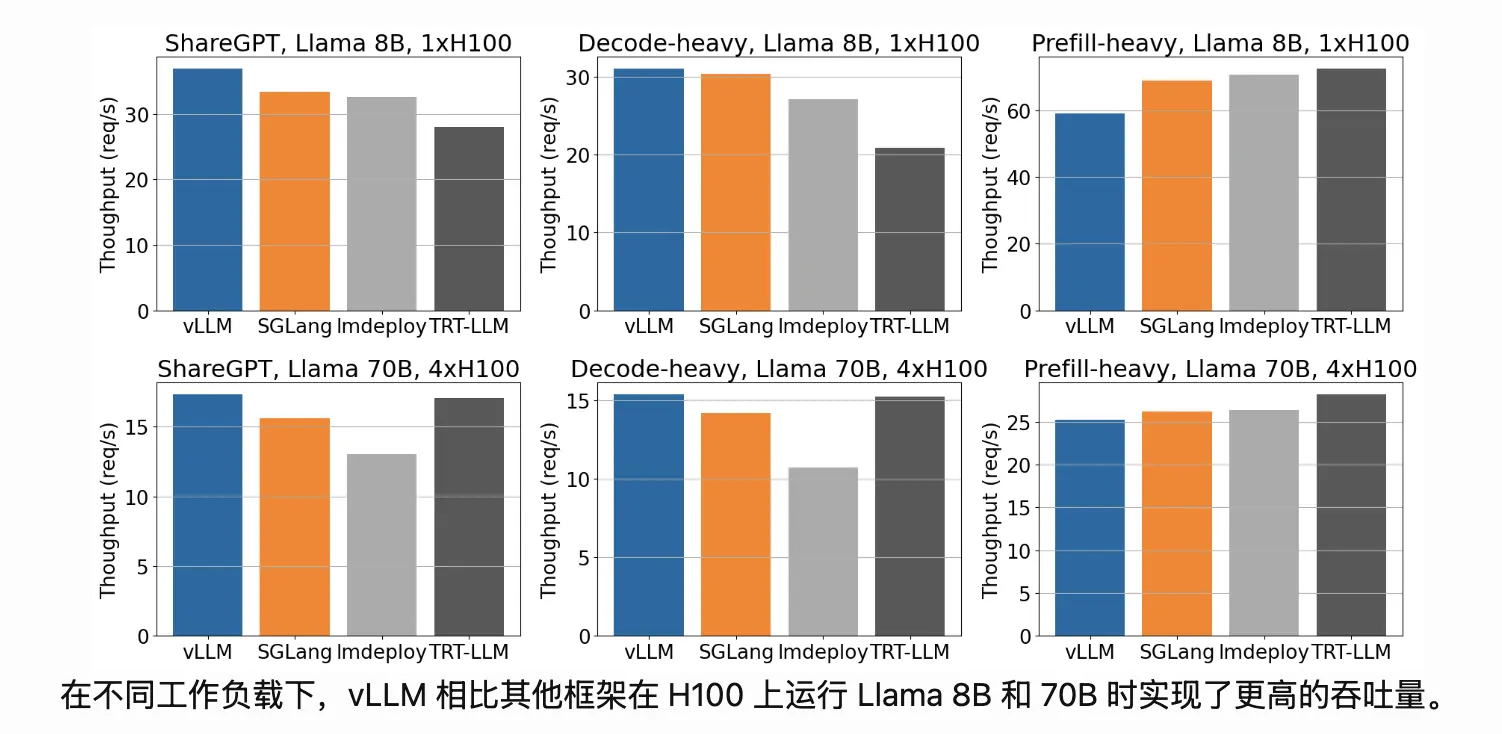
| 图编号 | 模型规模 & 卡数 | 任务类型 | vLLM 优势明显度 | 类型解释 |
|---|---|---|---|---|
| 图1 | LLaMA 8B, 1xH100 | ShareGPT | 明显 | 普通问答、多轮对话 |
| 图2 | LLaMA 8B, 1xH100 | Decode-heavy | 非常明显 | 长生成、解码占比高 |
| 图3 | LLaMA 8B, 1xH100 | Prefill-heavy | 小幅领先 | 长 prompt 输入任务 |
| 图4 | LLaMA 70B, 4xH100 | ShareGPT | 明显 | 大模型 + 对话场景 |
| 图5 | LLaMA 70B, 4xH100 | Decode-heavy | 极其明显 | 大模型 + 长文本生成 |
| 图6 | LLaMA 70B, 4xH100 | Prefill-heavy | 小幅领先 | 大模型 + 超长输入 |
另外一个测试数据:
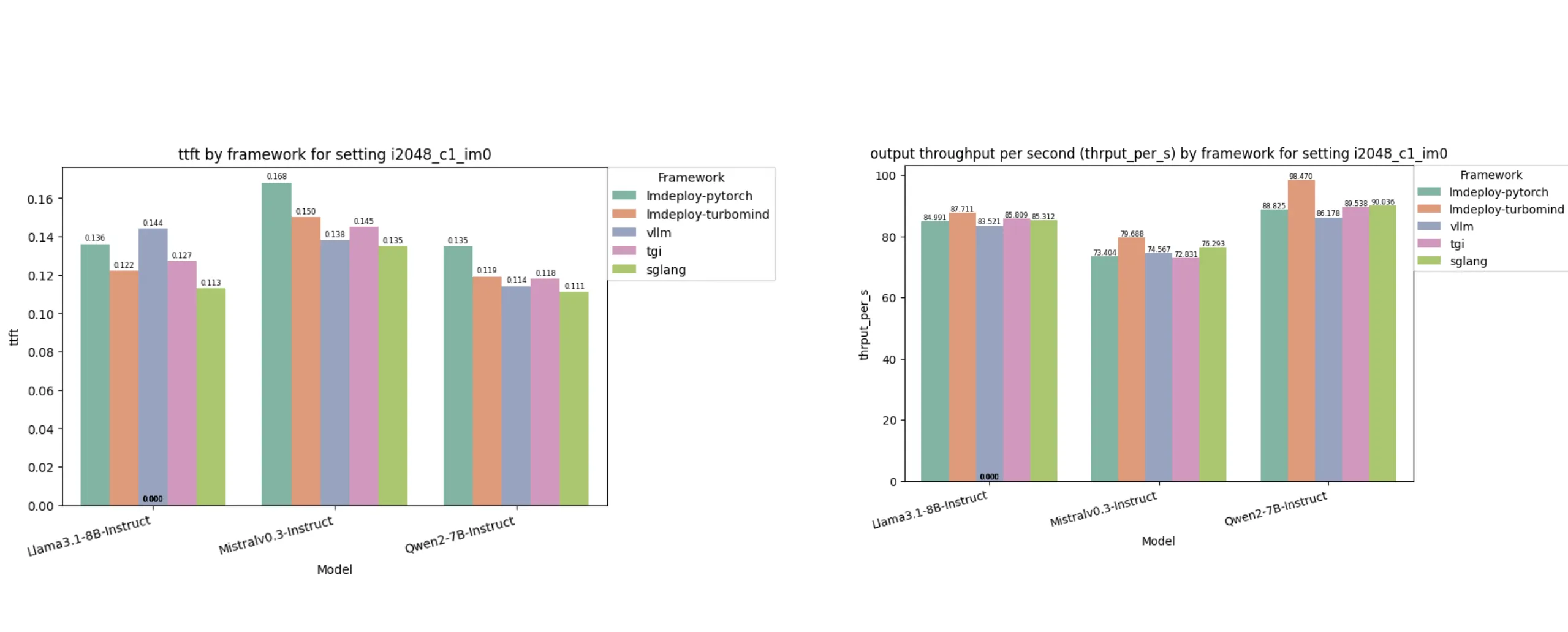
在单次请求处理时,SGLang 在首字延迟(ttfs)方面表现最佳,比最慢的(lmdeploy-pytorch)快 22.3%。
另一方面,lmdeploy-turbomind 以平均 88.6 tok/s 的速度领先其他方案,比最慢的(vllm)快 8.12%。
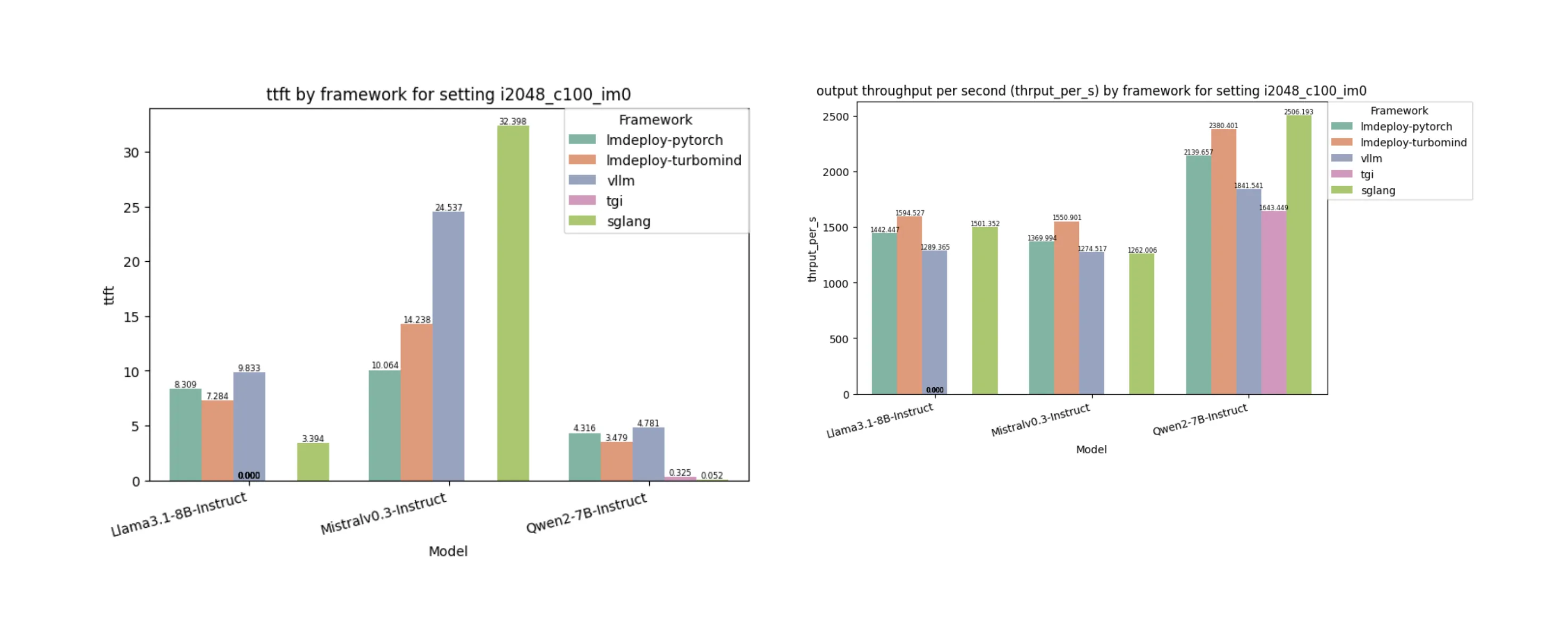
- 在 TTFS 方面,SGLang 在 3 个模型中有 2 个表现非常出色,但对 Mistralv0.3 的表现明显不足,即使经过多次重复测试结果依然一致。这表明该框架对 Mistral 架构的优化不足。
- 每秒吞吐量由 lmdeploy-turbomind 领先,比表现最差的框架高出 20%以上。
- TGI 在处理 Llama 和 Mistral 时均遇到内存不足(OOM)错误。
另外一个测试数据:
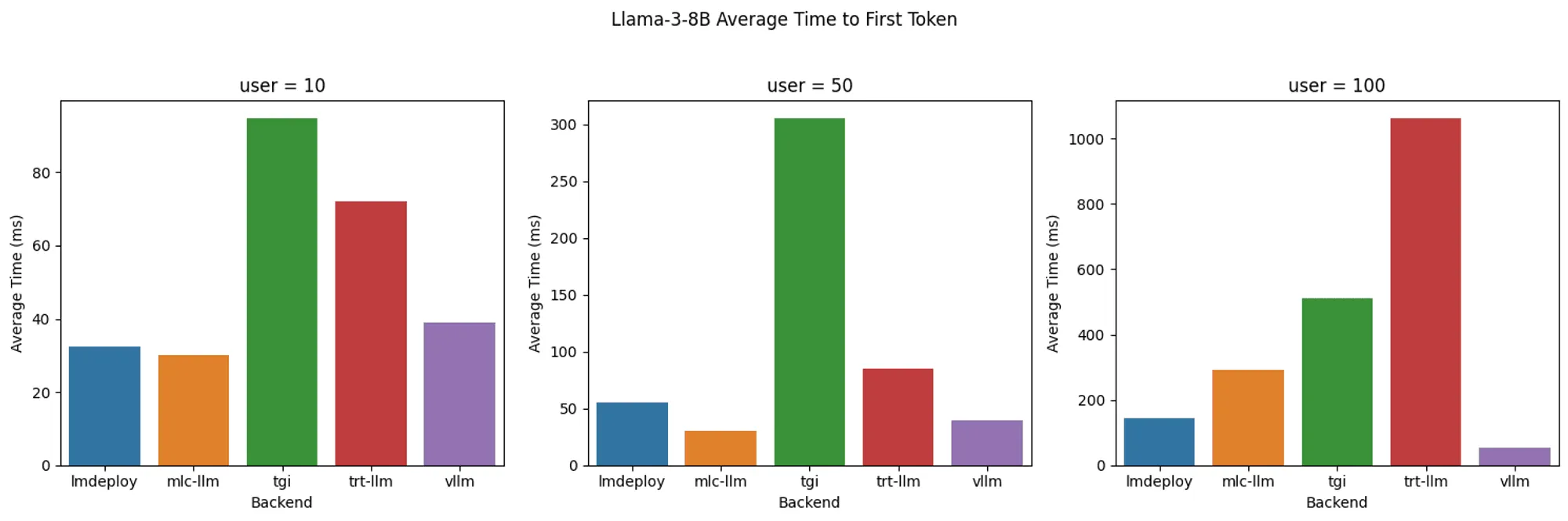
Llama 3 8B 模型:不同后端系统的首令牌响应时间(TTFT)对比
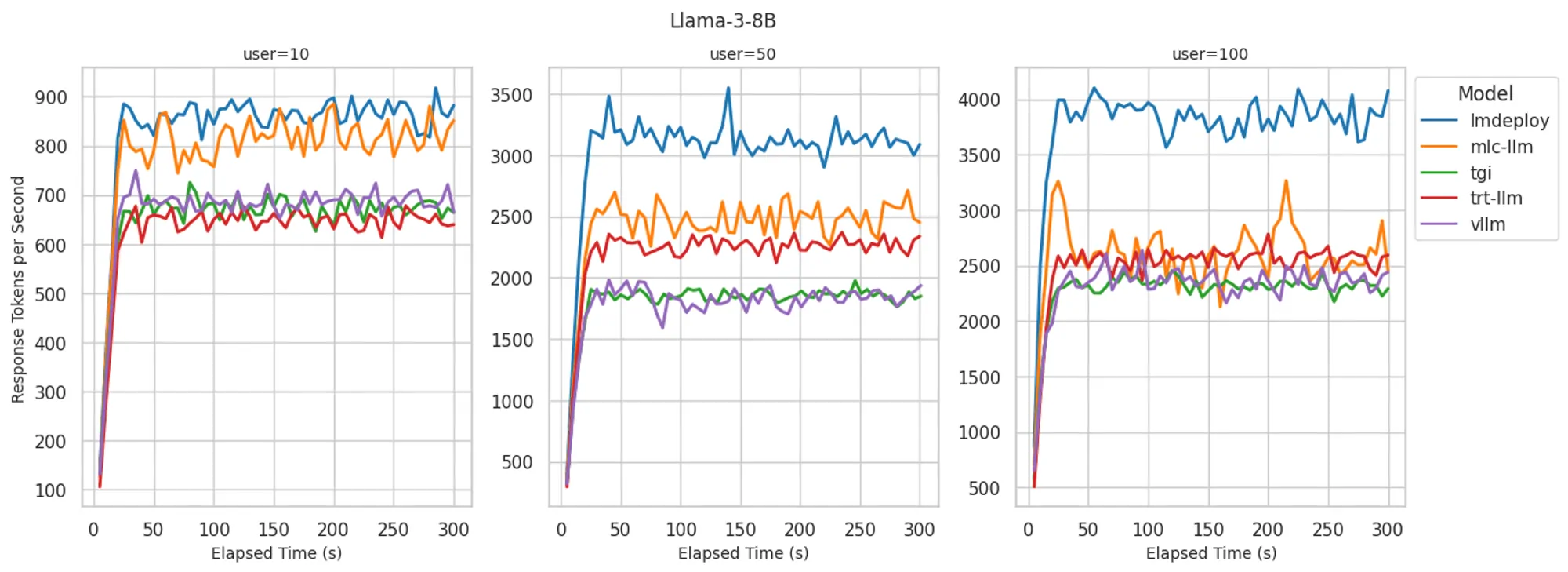
Llama 3 8B 模型:不同后端系统的令牌生成速率对比
- LMDeploy: 在令牌生成速率方面提供了最佳解码性能,100 用户并发时最高可达每秒 4000 个令牌。在 10 用户并发时实现了业界顶尖的首令牌响应时间。虽然随着用户数增加 TTFT 会逐步上升,但仍保持较低水平并始终位列最优表现。
- MLC-LLM: 在 10 用户并发时解码性能与 LMDeploy 相当,且在 10 和 50 用户时实现了业界领先的首字延迟(TTFT)。但在极高负载下难以维持该效率,当并发用户增至 100 时,其解码速度和 TTFT 表现均落后于 LMDeploy。
- vLLM: 在所有并发用户级别中均实现了最佳的首字延迟(TTFT),但解码性能较 LMDeploy 和 MLC-LLM 稍逊,每秒 2300-2500 个令牌的处理速度与 TGI 和 TRT-LLM 相近。
参考资源:
https://www.clarifai.com/blog/comparing-vllm-lmdeploy-and-sglang
https://www.bentoml.com/blog/benchmarking-llm-inference-backends
https://opencompass.readthedocs.io/en/latest/advanced_guides/accelerator_intro.html
https://www.clarifai.com/blog/comparing-vllm-lmdeploy-and-sglang
https://blog.vllm.ai/2024/09/05/perf-update.html
部署场景选择指南
根据应用场景选择
标准云服务部署
- 首选: vLLM
- 理由: 易于部署、广泛模型支持、活跃社区
中文/亚洲语言为主的应用
- 首选: LMDeploy
- 理由: 针对亚洲语言模型优化、良好的量化支持
需要极致性能的企业级部署
- 首选: TensorRT-LLM
- 理由: 最高性能、企业级支持、成熟的分布式能力
资源受限环境
- 首选: LMDeploy或TensorRT-LLM量化版
- 理由: 高质量的低精度推理实现
实践案例:DeepSeek模型的高性能部署
下面我们以DeepSeek模型为例,展示如何选择和使用高性能推理框架。
场景分析
假设我们需要部署一个DeepSeek-7B模型用于企业内部的智能客服系统:
- 需要处理约50个并发用户
- 要求响应速度快(首token<500ms)
- 硬件资源为2张A100-80GB GPU
- 需要支持长文本上下文
推理框架选择
基于上述需求,vLLM是较为合适的选择,原因如下:
- 良好的DeepSeek模型支持
- PagedAttention技术支持长上下文
- 优秀的并发处理能力
- 相对较低的部署复杂度
部署步骤概述
环境准备
- CUDA和PyTorch安装
- vLLM安装
模型准备
- 从HuggingFace下载DeepSeek模型
- 配置模型参数
服务部署
- 启动vLLM服务
- 配置API网关
性能测试与调优
- 负载测试
- 参数优化
推理优化的关键技术
无论选择哪种推理框架,以下关键技术都可以帮助优化LLM推理性能:
1. 模型量化
将模型参数从FP32/FP16降低到INT8/INT4等低精度格式:
- AWQ: 激活感知权重量化,保持高精度
- GPTQ: 基于量化感知训练的后训练量化
- SmoothQuant: 平滑量化,减少异常值影响
2. KV缓存优化
在自回归生成过程中优化注意力计算:
- PagedAttention/Blocked KV Cache: 分页管理KV缓存
- 注意力稀疏化: 减少不必要的注意力计算
- 上下文压缩: 长文档内容的智能压缩
3. 批处理策略
优化多请求处理:
- 连续批处理(Continuous Batching): 动态添加新请求
- 请求调度优化: 基于优先级和资源的请求排队
- 动态批大小: 根据负载自动调整批大小
4. 专用硬件加速
利用硬件特性:
- Tensor Core: NVIDIA GPU的专用矩阵计算单元
- 计算与访存重叠: 掩盖内存访问延迟
- 多级缓存优化: 提高数据局部性
5. 分布式推理
跨设备协同计算:
- 张量并行(Tensor Parallelism): 将单个计算分散到多GPU
- 流水线并行(Pipeline Parallelism): 模型层次的并行计算
- 专家并行(Expert Parallelism): MoE模型的专家分布
小结
高性能推理框架是将大语言模型部署到生产环境的关键工具。vLLM以其PagedAttention技术和易用性在通用场景中表现出色;LMDeploy在亚洲语言模型和量化方面具有优势;TensorRT-LLM则在NVIDIA硬件上提供极致性能和企业级功能。
在部署DeepSeek等大语言模型时,应根据具体应用场景、技术能力和资源条件选择合适的推理框架。同时,了解并应用关键的推理优化技术,如模型量化、KV缓存优化和批处理策略等,可以进一步提升推理性能和资源利用效率。
在下一节中,我们将深入探讨分布式与量化技术,这两项技术是实现大模型高效推理的关键所在。